How I Found All The Questions I've Ever Answered With LLMs
My latest Walden's World project is the Ask A Question page.
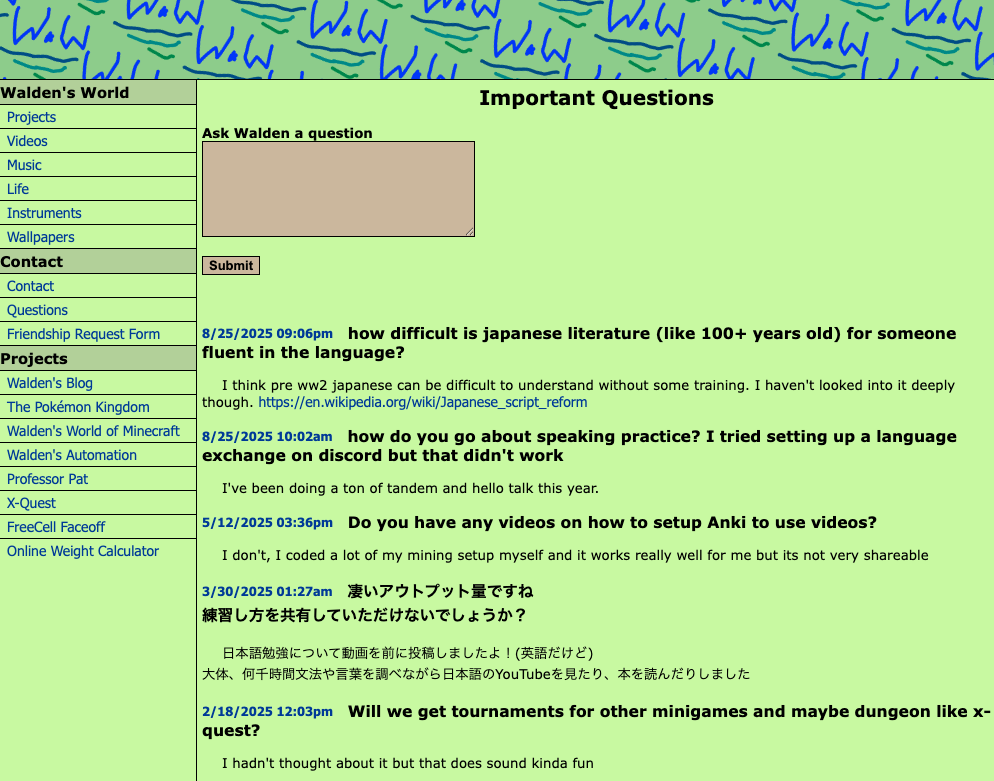
I wanted to make the questions page for a while, but it always felt a little sad that I'd be launching it with nothing there. I suddenly wanted to make the page though when I had an idea to go through my public chat history and pull in questions from my past.
Here are my sources:
- My Walden's World Discord server: 50,000 messages
- Chat logs from my various games: 3 million messages
- Comments across my various YouTube channels: 1,300 messages
Needless to say this is not super feasible by hand, so I thought LLMs could find these questions for me.
After a week, I'm finished and super happy with my results. This is the best practical LLM application project I've done so far. Out of those sources the LLMs found around 10k question/answer conversations, which I then vibe coded a web interface to quickly scan through and then manually selected around 350 for my website. The rest of this post is a breakdown of how I did it.
1. Discord
There's an open source project (DiscordChatExporter) for exporting chat logs from Discord. You can grab your Discord user account's token from the browser and run the tool as you, but technically it's against the discord TOS. Looking online, it seems a lot of people are running it without problems on main. Thankfully though, this is my server, so I have the option to create an official Discord bot and then add it to my server. That way I can use the bot's token instead of my user token. I'm really glad I had an official option because I'm not sure I would've taken any chance to risk a ban...
After the export, I had around 100MB of discord json message output. Time to start vibe coding a script to parse through this!
I've been using VS Code with GitHub Copilot as my coding agent. Right now I'm bouncing back and forth between GPT 5 Codex and Claude Sonnet 4. For the implementation I tried out having it make separate individually verifiable Python CLI scripts for the different sections: Discord json to text then LLM prompting from that json. Finally, I generated third python script to call both for me. I thought it was a clever way to verify each part was working as I built it, but it ended up being terrible because I lost the ability to debug into CLI scripts when running it together. At least I know for next time.
The final prompt I used to find questions & answers was this:
You are analyzing a chat log to extract question-answer pairs where the user "B0sh" provides answers to questions.
Please identify:
- Questions asked by any user in the chat
- Answers provided by the user "B0sh" to those questions
- The answer may be in the form of text, links, or mention of attachments
Rules:
- Only extract pairs where B0sh provides an answer
- A question-answer pair may span multiple messages, other people may talk in between the answer or questions.
- Include ALL original line text for both question and answer messages
- If B0sh's response mentions an attachment or image, include that as the answer
- Context matters - look for conversational flow to identify related Q&A
- For multi-message answers, include all B0sh messages that are part of the response
- For multi-message questions, include all messages that form the complete question
JSON Output format:
- question_lines: The exact original chat lines with usernames that form the question (may be multiple lines)
- answer_lines: The exact original chat lines with usernames where B0sh provides the answer (may be multiple lines)
In addition I used structured json outputs to enforce the json output requirements.
I let it rip on all my Discord channels which took around 15 minutes. With Gemini Flash 2.5 I felt like I was getting tons of inaccurate output. Mostly questions that I wasn't answering. I decided I'd rather just go through that garbage manually over further fine tuning the prompt. I spot checked Gemini Pro 2.5 as well, which was objectively better, but it was a huge price difference and I have a lot of tokens to burn through. Because of that, I added a validation script, which compared the AI outputs messages to the original chat log. It updated the json to flag any question that didn't have a match in the logs, so I could go through and review it if I so desired.
2. In Game Chat
Next, I have about 10 years of chat logs for my browser game. It's over 3 million messages, so I was starting to get worried about how much it would cost me. Discord was already a few dollars at 50,000 messages. That's when I had a realization.
Why analyze conversations where I'm not even participating? I'll be saving a lot of context (= cost) on messages I know won't be what I want. I'm shocked I didn't think of this the first time, but that's part of learning.
So, as part of the text extraction phase, I built conversations sections that included me. Every time I say something, it pulls the last 5 messages, then continues until I don't say anything for another 5 messages. This way conversations where I participate can have their whole context together. (Fun idea for a leetcode challenge here too) I also wanted to add batch processing this time to run multiple LLM calls in parallel.
Here's the final prompt I ended up using for the code:
Write me a simple batch LLM request python script in one file.
- It takes in an input file of a chat log.
- The chat log is
<USERNAME>: <MESSAGE>- First split the logs into sections where I'm talking. 5 messages before and after I (B0sh) talk should be in one section. This is so to not AI analyze conversations where I do not participate
- Write a prompt to extract questions and answers from the chat logs. It should only look for questions answered by "B0sh"
- Question and answer pairs should be returned in the json, with the original line of text. There may be more than one message for a single question and answer pair.
- The llm call should use the
llmcli tool to keep the code simple.Here's an example usage of the LLM command line:
llm -m openrouter/google/gemini-2.5-flash "prompt" --schema-multi 'json_prop_1,json_prop_2'
By the way, for both scripts so far I used the llm cli tool so I don't have to manage API keys in my code and lets me try different models out super easily.
My explanation of the buffer idea was insufficient, so I ended up ripping that part out and putting my own algorithm in. Somewhat poetically, this cut the message count to send to the LLM to around 50,000 as well, which is around the same message count as all of my Discord logs. However, the density of questions was extremely high as all of the messages had me involved this time. I had over 8,000 questions pulled from this part.
3. YouTube comments
This prompt worked one shot:
Write a python script in a new folder "/youtube" to pull all the comments from a youtube channel. Please note that I own the channel. Use uv over pip.
It correctly uses the YouTube API python library to loop over the videos in a channel and then loop over the comments. I happen to already have YouTube API key so configuring was fast too. This found around 1300 comments.
It was short enough that I figured I'd just go through them manually myself. Here is the prompt for the parser script:
<youtube_comments.json>write a script that takes this json and turns it into text based threads with author name and the text message. If its in a thread it should be obvious in the text only output that they are together. Don't put any other meta data other than the comment text and author
- at the end of the thread, show a sql script for the question answer like this:
INSERT INTO question_answers (question, answer, timestamp_asked, timestamp_answered, tags) VALUES ('
<QUESTION>', '<ANSWER>',<QUESTION_TIME>,<ANSWER_TIME>, 'youtube');
- The timestamps need to be converted into PHP unix time()
This text output was so much clearer than the JSON which was not in thread order, so I just scrolled through it and copied over the sql queries that I liked.
4. Question Viewer
For the first two sources I still had to go through the LLM question results. So the final piece to this project is an html/javascript viewer for the LLM json output with a "SQL copy" button so I could add it into my questions database.
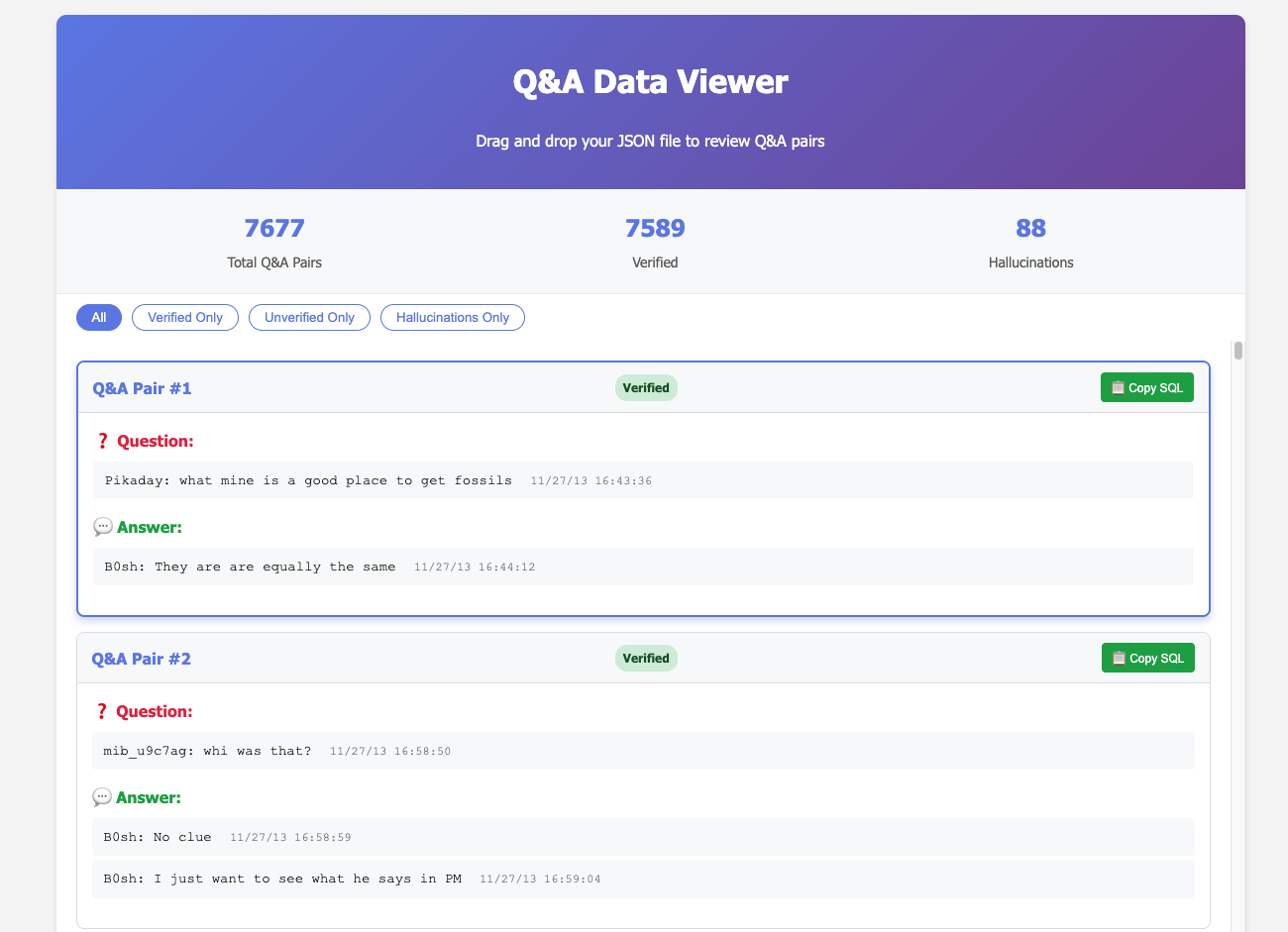
Here was the prompt I used:
<qa_results.json>code a simple js page to render this data so I can review it. allow the user to drag in the jsonInclude a "Copy SQL" button:
- It should copy an SQL insert query for this table: Table
question_answers: question, answer, timestamp_asked, timestamp_answered- The timestamps for PHP time() functions, so it should be converted into unix epoc
- Use the time of first message for asked and answered
- Remove usernames for question and answers, merge all messages into one text variable with new lines between
Notice I didn't care what the layout looked like, but I really needed my sql copy to be perfect. After a little more back and forth it was usable. It's saddening not to care about the code quality here, but I knew I would never use this again after the project concludes.
I had on the order of 10,000 questions to go through. I thought about sending it through another round of LLMs again to whittle it down further, but I just decided to parse through it all manually since I had a bunch of travelling coming up anyway. I didn't add anything to the prompt about filtering for "interesting" questions, only looking to see if a conversation was answering a question.
Talking about the final product, I know nobody cares about this silly thing as much as I do, but I love how Questions came out. I enjoyed the stroll down memory lane as much as the development.
This is personally my first project that the practical application of LLMs made possible. It's completely infeasible to review my entire public chat history for fun. It feels like a massive achievement to actually have "looked at" millions of messages and come out with some (according to me) interesting snippets to put on the site.
If you have any questions about this blog post, perhaps consider asking me a question.